Scritto da Ivana Basaric
I dati e la loro gestione sono diventati uno dei temi fondamentali per il mondo del business. Ma se in generale al centro della discussione sembrano essere i software per il data management, spesso si sottovaluta l'aspetto delle tecnologie che adoperiamo per salvare e gestire i dati. Sono davvero le migliori?
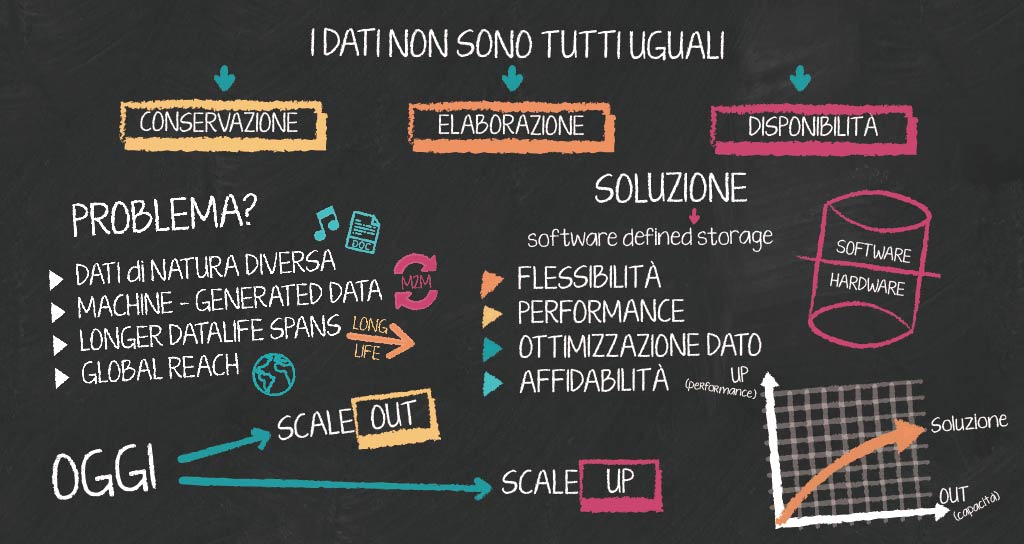
Da anni siamo stati abituati a gestire i dati in maniera omogenea commettendo errori. Il vero problema di oggi è che i dati non sono tutti uguali, ma vanno conservati, elaborati e resi disponibili in maniera diversa, rispettando la natura stessa del dato.
Partiamo quindi dai problemi che si riscontrano oggi sul mercato nella gestione corretta e funzionale dei dati:

I dati hanno natura diversa: le fotografie, cartelle o file video in HD, usate per una campagna pubblicitaria, sono molto diversi da un database organizzato e strutturato per conservare informazioni aziendali come per esempio quelli che riguardano la gestione della fatturazione.
Machine-generated data: grazie all’IoT i dati ormai vengono generati da apparati e dispositivi di qualsiasi tipo. I dati infatti possono, per esempio, provenire da automobili che informano sulla pressione delle gomme oppure da un gasdotto che ci informa sulla quantità di litri di gas che passano in un determinato arco di tempo.
Longer data life spans: i dati che devono essere archiviati e conservati a lungo termine. Parliamo della necessità di mantenerli accessibili per mesi o anni. Ma non solo! I dati devono essere anche recuperabili in maniera veloce e semplice.
Global reach: anche se i dati possono essere salvati in data center locali o in siti remoti come quelli dei provider di private cloud o su cloud pubblici, devono essere resi sempre disponibili ovunque come se si trovassero tutti in un unico punto.
Di fronte a uno scenario così complesso, ci chiediamo quindi se le tecnologie che abbiamo sempre usato per gestire dati, che ormai hanno preso una strada evolutiva decisamente diversa, sono adatte.

Se analizziamo le tecnologie usate per conservare i dati, ovvero gli storage adoperati fino a oggi, ci accorgiamo che dovevamo scegliere tra due opzioni, ovvero tra una tecnologia scale up o quella scale out.
Nel caso di una tecnologia scale up è possibile assicurare alti livelli di performance, ma limiti in capacità disco e scalabilità. Si tratta dei classici storage “silos” che vengono controllati da diversi controller (solitamente 2) che ne gestiscono l’intelligenza, collegati a loro volta a una batteria di dischi.
Gli storage scale out garantiscono invece una capacità disco elevata, ma performance inferiori. Sono caratterizzati dal raggruppamento di diversi storage dove ciascuno di questi a sua volta ha i suoi controller e batterie di dischi.
Ad oggi prese singolarmente queste tecnologie non rispondono più alle esigenze che hanno le aziende visto che c’è sempre più la necessità di unire la performance alla scalabilità e capacità. Le aziende devono salvare grandi quantità di dati, ma allo stesso tempo avere la possibilità di accedervi e farli funzionare velocemente. Un esempio pratico? Provate a pensare a un video in HD, dobbiamo avere disponibilità di grande spazio per conservarlo (spesso parliamo di TB), ma questo deve anche essere riprodotto in streaming con elevate performance di lettura e scrittura.
Software Defined Storage: una soluzione che permette di coniugare performance e capacity

La soluzione che per noi oggi offre la possibilità di ottenere scalabilità, sia sulla performance che sulla capacità, è la cosiddetta tecnologia Software Defined Storage caratterizzata da una parte software separata da quella hardware. Proprio per questa sua struttura l’utente può:
Avere maggiore flessibilità in quanto non siamo più legati ad una logica di crescita scale up perché, grazie alla possibilità di aggiungere nodi (per nodi intendiamo server con capacità disco interna e capacità computazionale) che vengono raggruppati con tecnologie di software avanzate, viene garantita l’aggiunta di spazio;
Assicurarsi performance elevate perché aggiungendo nodi di fatto aumentiamo anche la performance perché ogni nodo ha la capacità computazionale che contribuisce alla capacità globale di elaborazione, aumentando le prestazioni prendendo il meglio dalle logiche di scale up e scale out.
Avere un’ottimizzazione del dato grazie a tecnologie di cashing o SSD viene ottimizzata la capacità di lettura e scrittura, mentre la gestione dello spazio è migliorata con operazione come la deduplica e la compressione. Infatti la deduplica dei dati è un processo che elimina le informazioni ripetute in modo da incrementare la disponibilità dello storage e per migliorare l'efficienza dell’occupazione della banda. La compressione invece funziona come una sorta di “zip” dei file, in cui un meccanismo comprime il dato ottimizzando lo spazio che questo occupa.
Rendere affidabile il dato perché questa tecnologia permette di poter replicare il singolo dato su diversi dischi o diversi nodi e anche su diversi site in modo semplice e flessibile
Permettere gestione semplificata e centralizzata grazie alla presenza di una sola dashboard avanzata che permette di avere un unico punto di controllo sull’utilizzo di risorse. Questa dashboard agevola inoltre la predittività sui failure che avvengono all’interno della soluzione grazie a elementi avanzati di analytics e intelligenza artificiale.
Avere gli update del software che avvengono live permettendo di effettuare aggiornamenti di sicurezza critici senza implicare downtime della disponibilità del dato.
Vuoi sapere di più sul Software Defined Storage e avere degli esempi pratici sul funzionamento?
Scarica il White Paper di Qumulo.